

The surge of artificial intelligence (AI) and machine learning (ML) across billions of devices has reinvented the way societies around the world learn, work and function. Voice-based services and technologies like Siri and Google Assistant continue to create seamless and hands-free experiences that transform our lives. However, in this ever-evolving digital world, the privacy obligations and security issues associated with speech data cannot be overlooked, and a team in China has introduced a new system that enhances privacy protection in speech data publishing.
While major companies aim to delete all personally identifiable information (PII) of users’ speech data, such as their name, phone number and email when improving voice-based services, cyber-attacks continue to increase. Partial anonymization is not enough. Current systems fail to consider the correlation between speech content – the text or words in the speech – and a speaker’s voice, making it easier for attackers to filter out the sanitized – or altered – parts of speech data and identify sensitive information. An example of such a scenario is illustrated in Figure 1.
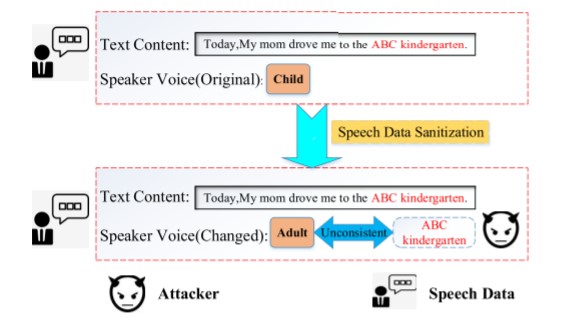
Figure 1: Speech content is not consistent with the speaker’s voice once sanitized
Companies or institutions can attempt to sanitize the data by altering a given voice from a child to an adult, in order to mask the speaker’s age, but the content itself remains the same. This allows attackers to spot inconsistencies in the conversation and narrow down the speaker’s actual age.
Additionally, in today’s digital landscape, anonymous data is often not significantly anonymous. Companies and organizations that believe in anonymity can be susceptible to linkage attacks, whereby attackers attempt to de-anonymize data sets.
As outlined in Figure 2, adversaries collect secondary information about an individual from multiple data sources and then comb through that data to form a full profile. The more a company attempts to preserve the analytical utility of the dataset, such as keeping “gender” and “date of birth” information in the dataset, the more they are prone to linkage attacks, even if they remove the PII from the data. Attackers could cross-reference public records with attributes obtained from analyzing speech data to match and determine the identity of the PII-removed individual.
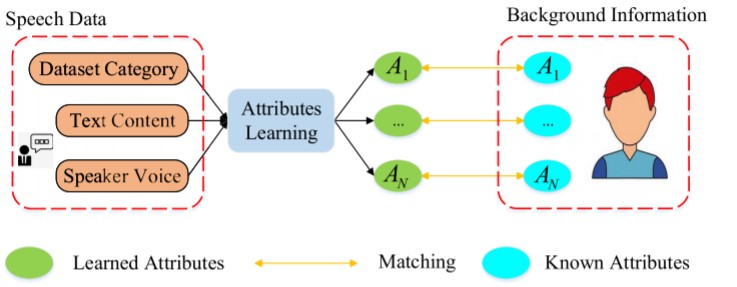
Figure 2: The process of a linkage attack
According to Sifan Ni, a researcher at Donghua University in China, it’s challenging to protect user information when publishing speech data. This data already contains personal and private information, from favorite hobbies and personal preferences to spending habits, which helps attackers determine the identity of the speaker. The key is finding the appropriate balance between speech privacy and data utility.
By focusing on three dimensions, speech content, speaker’s voice and data set description, the team’s privacy-preserving method minimizes potential risks in speech data publishing, while preserving the analytical utility of the data. Through a series of privacy risk and utility loss indicators, the system can quantify the influence of speech data sanitization on the diversity of the data set and the quality of the speech.
Additionally, incorporating numerous sanitization methods that address these three dimensions reduces the risk of sensitive information leaking, while also guaranteeing the utility of the speech data. Overall, by analyzing the impact of these sanitization methods against the risk and utility loss indicators, the system achieves the optimal trade-off between privacy leakage risks and utility loss in speech data publishing. Figure 3 outlines the team’s approach.
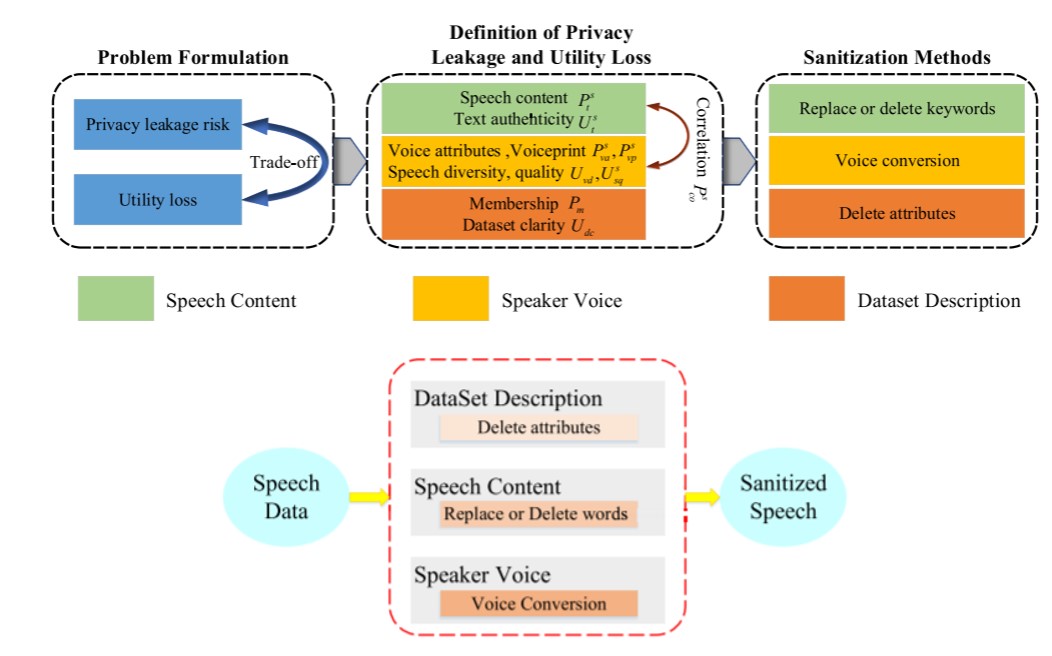
Figure 3: The team’s privacy preserving and sanitization method for speech publishing
“We utilize the TF-IDF based algorithm to calculate the importance of each word in the speech content to decrease leakage risks [and quantify utility loss]” said Sifan. “Our sanitization [methods] consists of replacing or deleting the words in speech content, changing the frequency of speaker's voice, and deleting the keywords in the dataset description.”
As seen in today’s cyber-attacks, securing data across multiple data silos is challenging, and solutions to preserve privacy have sparked countless debates in the last decade. Sifan and his team believe there is a trade-off between preventing privacy breaches and minimizing utility loss of the speech data, for now. As a next step, the team is exploring whether novel metrics exist that better represent privacy risks and utility loss.
For more information on data privacy and machine learning, visit the IEEE Xplore digital library.



