

Since the early decades of artificial intelligence (AI), humanoid robots have been a staple of sci-fi books, movies, and cartoons. After decades of research and development in AI, we are still a long way from having humanoid robots as part of daily life. Many of our intuitive planning and motor skills—things we take for granted—are much more complicated than we think. Navigating unknown areas, finding and picking up objects, choosing routes, and planning tasks are complex acts that we only appreciate when we try to turn them into computer programs.
Task and Motion Planning (TAMP) problems combine discrete task planning and continuous motion planning. According to an article in IEEE Robotics and Automation Letters, the interplay between the two planning levels gives more comprehensive solutions which consider both logical and geometric constraints. Researchers have integrated a vision-based Reinforcement Learning (RL) non-prehensile procedure, pusher, to extend the ability of sampling-based algorithms.
Robotic manipulation in cluttered environments requires synergistic planning among prehensile and non-prehensile actions. Previous works on sampling-based TAMP algorithms fail in cluttered scenarios where no collision-free grasping approaches can be sampled without preliminary manipulations. The researchers outline their novel methods and analyze the learning performance of the presented framework.
Every Problem Has a Solution
According to the article, the pushing actions generated by the pusher can eliminate interlocked situations and make the grasping problem solvable. For a cluttered bin pick-and-place task, the robot needs to push the objects into a situation where they can be grasped with a specific task sequence and grasp position. The TAMP solution can solve the problem by planning a rational task sequence and grasping pose. As for the pushing actions, dead-end situations such as pushing objects to the corner of the bin or colliding with the bin should be avoided.
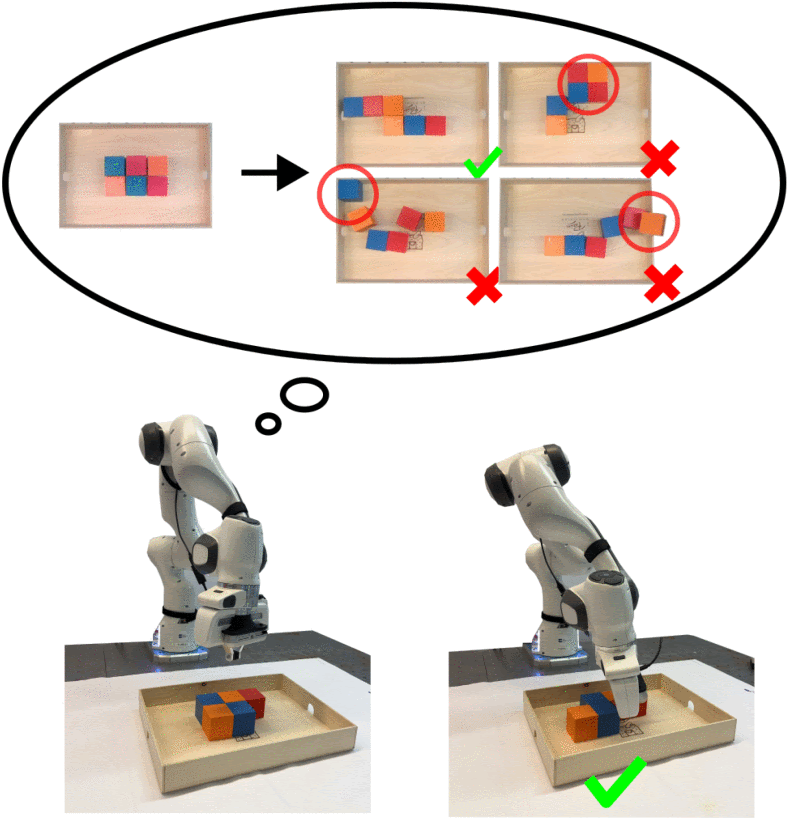
Cluttered bin pick-and-place task
The sampling-based pick solver can efficiently solve deterministic problems such as pick-and-place when the situation is solvable. At the same time, the vision-based Reinforcement Learning (RL) pusher can plan non-prehensile actions with stochastic effects. According to the researchers, the two modules work interactively: the pusher helps to unlock the current interlock situation that prevents the pick solver from making further moves, while the pick solver evaluates the pusher’s actions during training by giving rewards.
With the proposed hybrid planner, the pick solver plans task sequences and motion trajectories for pick-and-place, requests pushing actions from the pusher when the objects are jammed together, and no further pick-and-place actions can be planned. The hybrid planner coordinates the abilities of RL and Planning Domain Definition Language (PDDL) Stream and provides a novel perspective for the cluttered bin-picking problem. The article also presents a novel reward shaping strategy for robotic RL and improves the ability of the PDDLStream method to work in a cluttered environment.
Methodology
According to the researchers, the sampling-based pick solver can solve actions with deterministic effects, such as picking with known object positions, which avoids the lengthy training process. However, actions with stochastic effects, such as pushing and sampling-based algorithms, require continuous forward simulation to sample a valid action. Without rational guidance, the sampling process with forward simulation can be time-consuming. Instead, the RL-based data-driven algorithm leverages previous experience and provides reasonable actions as split-second reactions from observation.
The structure of the proposed hybrid TAMP planner is composed of a RL pusher and a PDDLStream pick solver; the two parts function interactively. The scenario is the cluttered bin-picking environment in simulation or the real world. During training, the pick solver sends requests when there are no solvable objects and evaluates the pusher’s behavior by giving rewards. Therefore, the pusher can effectively learn to create a solvable situation for the pick solver.
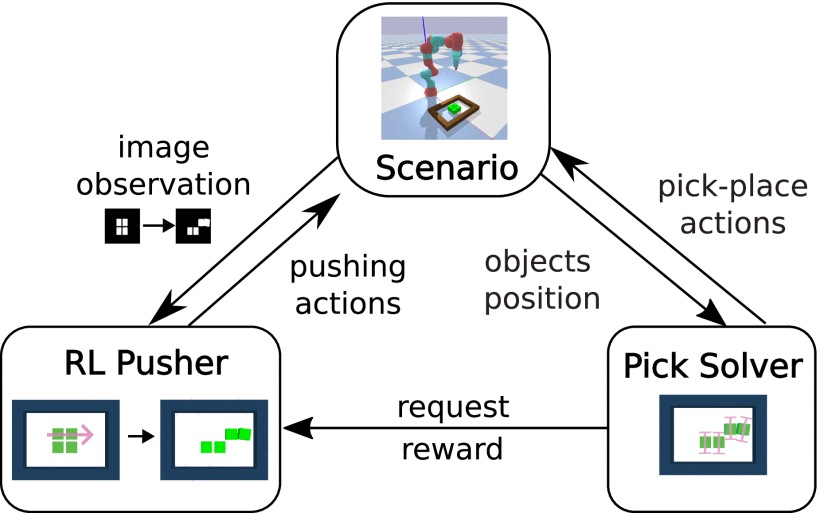
Fig. 2.
Hybrid TAMP planning method structure.
Each scenario follows the outlined Markov Decision Process, Reinforcement Learning Pusher, Sampling-Based Pick Solver, Action Validity Check, and Reward Shaping. After the validity check, the method uses the solvability of the current state to evaluate the pushing action. Intuitively, in the cluttered manipulation domain, the more separate the objects are, the easier the pick solver will find a plan since the stream can easily sample collision-free grasping poses.
The article outlines the experiments implemented and the corresponding results. By interactively activating the pick solver and RL pusher, the cluttered bin-picking problem can be solved. Not surprisingly, the success ratio declines in the real world, which can be caused by physics differences and the noise of actual camera observations. To extend the ability of the method, the researchers show the potential to develop the algorithm for objects with other shapes.
The proposed hybrid planning method is validated on a cluttered bin-picking problem and implemented in both simulation and the real world. Results show that the pusher can effectively improve the success ratio of the previous sampling-based algorithm, while the sampling-based algorithm can help the pusher learn pushing skills.
Next Steps
Near the end of the article, the researchers discuss the potential for future research, including customizing a RL environment for the specific cluttered bin-picking domain. RL environments must be tuned, and the current method requires retraining processes on new domains. A more general presentation on domains with diverse non-prehensile actions should be studied.
Interested in acquiring full-text access for your entire organization? Full articles available with purchase or subscription. Contact us to see if your organization qualifies for a free trial.



